
Today you are a machine learning engineer on the Spatial Perception Team (SPT) at Apple. The goal is to levarage an existing object detector model to automatically detect dogs, an application of transfer learning.
The idea is that you have access to a model that you or one of your colleagues has already trained on a large and diverse set of images, but the model is not very specific for your task (dog detection). We'll do transfer learning by fine-tuning this existing model on a small dataset of dog images.
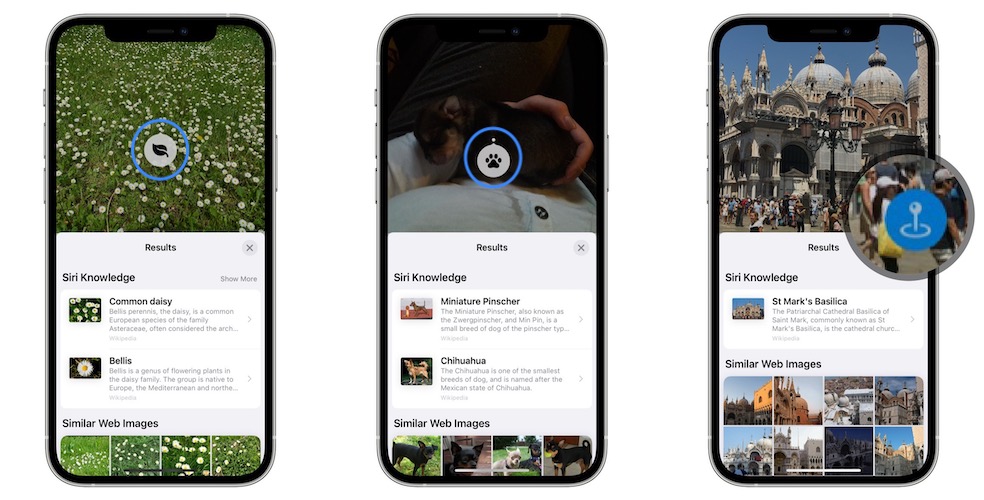
This is only a small part of the end product -- Visual Look Up feature released in iOS 15 -- snap a picture, identify if an object belonging to five categories (art, landmarks, nature, books, and pets) exists, if yes, highlight with a object symbol, and further identify, e.g., the species of a plant. Examples are shown below (picture credits)
At the end of this session, you will be able to
We will run this notebook via Google Colab to take advantage of its free GPU computing power and avoid installation pain.
It is however not hassle-free, three steps to ensure no errors running this notebook for the time being (this looks familiar to you if you have run the demo notebook):
Runtime > Disconnect and delete runtimeRuntime > Change runtime typetensorflow 2.8, as well as the compatible GPU-accelerated library; solution is based on this issue. Depending on the internet connection, it could take a few minutes to finish.!pip install -U -q tensorflow==2.8
!apt install --allow-change-held-packages libcudnn8=8.1.0.77-1+cuda11.2
\ 668.3 MB 6.0 MB/s
|████████████████████████████████| 462 kB 27.2 MB/s
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
libnvidia-common-460
Use 'apt autoremove' to remove it.
The following packages will be REMOVED:
libcudnn8-dev
The following held packages will be changed:
libcudnn8
The following packages will be upgraded:
libcudnn8
1 upgraded, 0 newly installed, 1 to remove and 47 not upgraded.
Need to get 430 MB of archives.
After this operation, 3,139 MB disk space will be freed.
Get:1 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 libcudnn8 8.1.0.77-1+cuda11.2 [430 MB]
Fetched 430 MB in 7s (64.6 MB/s)
(Reading database ... 155639 files and directories currently installed.)
Removing libcudnn8-dev (8.0.5.39-1+cuda11.1) ...
(Reading database ... 155617 files and directories currently installed.)
Preparing to unpack .../libcudnn8_8.1.0.77-1+cuda11.2_amd64.deb ...
Unpacking libcudnn8 (8.1.0.77-1+cuda11.2) over (8.0.5.39-1+cuda11.1) ...
Setting up libcudnn8 (8.1.0.77-1+cuda11.2) ...
Use the NVIDIA System Management Interface to check the GPU device you are on.
!nvidia-smi
Sat Jul 2 03:52:31 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 42C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
import pathlib
# Clone the tensorflow models repository if it doesn't already exist
if "models" in pathlib.Path.cwd().parts:
while "models" in pathlib.Path.cwd().parts:
os.chdir('..')
elif not pathlib.Path('models').exists():
!git clone --depth 1 https://github.com/tensorflow/models
Cloning into 'models'... remote: Enumerating objects: 3406, done. remote: Counting objects: 100% (3406/3406), done. remote: Compressing objects: 100% (2837/2837), done. remote: Total 3406 (delta 895), reused 1411 (delta 512), pack-reused 0 Receiving objects: 100% (3406/3406), 34.96 MiB | 12.67 MiB/s, done. Resolving deltas: 100% (895/895), done.
%%bash
sudo apt install -y protobuf-compiler
cd models/research/
protoc object_detection/protos/*.proto --python_out=.
cp object_detection/packages/tf2/setup.py .
python -m pip install -q -U .
Reading package lists... Building dependency tree... Reading state information... protobuf-compiler is already the newest version (3.0.0-9.1ubuntu1). The following package was automatically installed and is no longer required: libnvidia-common-460 Use 'sudo apt autoremove' to remove it. 0 upgraded, 0 newly installed, 0 to remove and 48 not upgraded.
WARNING: apt does not have a stable CLI interface. Use with caution in scripts. DEPRECATION: A future pip version will change local packages to be built in-place without first copying to a temporary directory. We recommend you use --use-feature=in-tree-build to test your packages with this new behavior before it becomes the default. pip 21.3 will remove support for this functionality. You can find discussion regarding this at https://github.com/pypa/pip/issues/7555. ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. multiprocess 0.70.13 requires dill>=0.3.5.1, but you have dill 0.3.1.1 which is incompatible. gym 0.17.3 requires cloudpickle<1.7.0,>=1.2.0, but you have cloudpickle 2.1.0 which is incompatible. google-colab 1.0.0 requires requests~=2.23.0, but you have requests 2.28.1 which is incompatible. datascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible. albumentations 0.1.12 requires imgaug<0.2.7,>=0.2.5, but you have imgaug 0.2.9 which is incompatible.
Make sure to upload the folder dog_dataset containing all images and annotation files to your google drive /content/drive/My Drive/fourthbrain/dog_dataset.
Retrieve a list containing the names of the training images in the directory given by train_image_dir. Use os.listdir and store the results to image_names; e.g.,
image_names[0] # dog_004.jpg
import os
dog_dataset_path = '/content/drive/My Drive/Colab Notebooks/dat/dog_dataset' # Replace with actual path
train_image_dir = os.path.join(dog_dataset_path, 'train/images')
image_names = sorted(os.listdir(train_image_dir))
image_names
['dog_001.jpg', 'dog_002.jpg', 'dog_003.jpg', 'dog_004.jpg', 'dog_005.jpg', 'dog_006.jpg', 'dog_007.jpg', 'dog_008.jpg', 'dog_009.jpg', 'dog_010.jpg']
assert len(image_names) == 10
Function load_image_into_numpy_array() below is provided to load the an image given path.
Examine the code and use it to read all the training images and store them in list train_images_np.
import tensorflow as tf
from PIL import Image
from six import BytesIO
import numpy as np
def load_image_into_numpy_array(path):
"""
Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: a file path.
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
img_data = tf.io.gfile.GFile(path, 'rb').read()
image = Image.open(BytesIO(img_data))
im_width, im_height = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
train_images_np = [load_image_into_numpy_array(train_image_dir+"/"+name) for name in image_names]
# YOUR CODE HERE
assert len(train_images_np) == 10
assert train_images_np[0].shape == (480, 640, 3)
for i in range(len(train_images_np)):
print("Shapes of image:--",i,train_images_np[i].shape)
Shapes of image:-- 0 (480, 640, 3) Shapes of image:-- 1 (480, 640, 3) Shapes of image:-- 2 (480, 640, 3) Shapes of image:-- 3 (480, 640, 3) Shapes of image:-- 4 (480, 640, 3) Shapes of image:-- 5 (480, 640, 3) Shapes of image:-- 6 (480, 640, 3) Shapes of image:-- 7 (480, 640, 3) Shapes of image:-- 8 (480, 640, 3) Shapes of image:-- 9 (480, 640, 3)
train_images_np[0].shape
(480, 640, 3)
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 6))
for idx, train_image_np in enumerate(train_images_np):
ax = plt.subplot(2, len(train_images_np) / 2, idx + 1)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
plt.imshow(train_image_np)

Recall our task is to detect where the dog is in the image.
The object detection model we'll use spits out bounding boxes where it thinks there might be an object. For each bounding box, it also makes a prediction of which class the object is from, and there is an associated "score", or confidence, of this prediction.
The format for specifying bounding boxes of our training data and the model outputs are [$y_{\min}$, $x_{\min}$, $y_{\max}$, $x_{\max}$], where $y$ is the vertical position and $x$ is the horizontal position. For example, a bounding box of [0.1, 0.15, 0.8, 0.9] means one whose lower left corner is at position (0.1, 0.15) and whose upper right corner is at (0.8, 0.9).
These values, ranging between 0 and 1, are agnostic to the size of the image, if you wanted to convert them to pixels you would multiply by the width or height of the image (in pixels).
We will use function visualize_boxes_and_labels_on_image_array in the object detection visualization utilities to display the bounding boxes overlaid on an image.
First, though, let's read annotations (including the ground-truth bounding boxes) for these training images.
read_content() given below to read in all the annotations and save them in a list gt_boxes.import xml.etree.ElementTree as ET
from typing import Tuple
def read_content(xml_file: str, h: int, w: int) -> Tuple[str, list]:
""" parse metadata/annotation
Args:
xml_file (str): path to a xml file
h (int): height
w (int): width
Return:
Tuple[str, list]:
"""
tree = ET.parse(xml_file)
root = tree.getroot()
list_with_all_boxes = []
for boxes in root.iter('object'):
filename = root.find('filename').text
ymin, xmin, ymax, xmax = None, None, None, None
ymin = int(boxes.find("bndbox/ymin").text) / h
ymax = int(boxes.find("bndbox/ymax").text) / h
xmin = int(boxes.find("bndbox/xmin").text) / w
xmax = int(boxes.find("bndbox/xmax").text) / w
list_with_single_boxes = [ymin, xmin, ymax, xmax]
list_with_all_boxes.append(list_with_single_boxes)
return filename, list_with_all_boxes
#check document for bounding boxes, what parameters passing yx, or x y
#and normalizations
train_ann_dir = os.path.join(dog_dataset_path, 'train/annotations')
ann = os.listdir(train_ann_dir)
gt_boxes = []
for image in image_names:
ann_path = os.path.join(train_ann_dir,image[:-3]+"xml") #xml read this
gt_name, gt_box_ea = read_content(ann_path,480,640) # all images have the same dimension, if not suggested to paddding to the same dim.
gt_boxes.append(np.array(gt_box_ea))
# YOUR CODE HERE
gt_boxes[0]
array([[0.25208333, 0.2359375 , 0.72083333, 0.9015625 ]])
assert len(gt_boxes) == len(train_images_np)
dog_class_id = 1
num_classes = 1
category_index = {dog_class_id: {'id': dog_class_id, 'name': 'dog'}}
label_id_offset = 1
train_image_tensors = []
gt_classes_one_hot_tensors = []
gt_box_tensors = []
for train_image_np, gt_box_np in zip(train_images_np, gt_boxes):
train_image_tensors.append(
tf.expand_dims(
tf.convert_to_tensor(train_image_np, dtype=tf.float32),
axis=0))
gt_box_tensors.append(tf.convert_to_tensor(gt_box_np, dtype=tf.float32))
zero_indexed_groundtruth_classes = tf.convert_to_tensor(
np.ones(shape=[gt_box_np.shape[0]], dtype=np.int32) - label_id_offset)
gt_classes_one_hot_tensors.append(
tf.one_hot(zero_indexed_groundtruth_classes, num_classes))
visualize_boxes_and_labels_on_image_array() to plot these bounding boxes on their respective images. Look at the images which show the dogs corrected identified in each image.from object_detection.utils import visualization_utils as viz_utils
dummy_scores = np.array([1.0], dtype=np.float32)
plt.figure(figsize=(20, 3))
for idx in range(5):
ax = plt.subplot(1, 5, idx + 1)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
temp_img_copy = np.copy(train_images_np[idx])
viz_utils.visualize_boxes_and_labels_on_image_array(
temp_img_copy,
gt_boxes[idx],
np.ones(shape=[gt_boxes[idx].shape[0]], dtype=np.int32),
dummy_scores,
category_index,
use_normalized_coordinates=True,
min_score_thresh=0.0)
plt.imshow(temp_img_copy)
print(f'Bounding box for image {idx}: ', gt_boxes[idx])
Bounding box for image 0: [[0.25208333 0.2359375 0.72083333 0.9015625 ]] Bounding box for image 1: [[0.30833333 0.18125 0.65208333 0.66875 ]] Bounding box for image 2: [[0.00208333 0.0015625 0.46875 0.528125 ]] Bounding box for image 3: [[0.1875 0.253125 0.81666667 0.6171875 ]] Bounding box for image 4: [[0.15 0.1984375 0.9375 0.71875 ]]

Follow the similar process to load test images and save them in list test_images_np, except that each image is expected in NHWC format with N set to be 1. Hint: use np.expand_dims.
Check Table 1. Parameters defining a convolution for what each letter means in format such as NHWC.
%%time
test_images_np = []
test_image_dir = os.path.join(dog_dataset_path, 'test/images')
t_image_names = sorted(os.listdir(test_image_dir))
test_images_np = [np.expand_dims(load_image_into_numpy_array(test_image_dir+"/"+name),axis=0) for name in t_image_names]
# YOUR CODE HERE
CPU times: user 8.17 s, sys: 660 ms, total: 8.83 s Wall time: 42.8 s
test_images_np[0].shape
(1, 480, 640, 3)
assert len(test_images_np) == 40
assert test_images_np[0].shape == (1, 480, 640, 3)
t_gt_boxes.t_gt_boxes = []
test_ann_dir = os.path.join(dog_dataset_path, 'test/annotations/xmls')
t_xml_names = sorted(os.listdir(test_ann_dir))
for xml in t_xml_names:
ann_path_t = os.path.join(test_ann_dir,xml[:-3]+"xml") #xml read this
gt_name_t, gt_box_ea_t = read_content(ann_path_t,480,640) # all images have the same dimension, if not suggested to paddding to the same dim.
t_gt_boxes.append(np.array(gt_box_ea_t))
# YOUR CODE HERE
t_gt_boxes[0]
array([[0.36875 , 0.38125 , 0.79583333, 1. ]])
assert len(test_images_np) == len(t_gt_boxes) == 40
Download the checkpoint and put it into models/research/object_detection/test_data/.
This model is an SSD (single shot multibox detector) object detetion with Resnet50 backbone with feature pyramid network. You can choose other models, such as YOLO, feasterRCNN, etc.
Note. For simplicity, a number of things in this notebook is harcoded for the specific RetinaNet architecture at hand, including assuming that the image size will always be 640x640.
Another note. TensorFlow Hub is now the repository of trained machine learning models (TensorFlow Hub Object Detection Colab tutorial), however it seems that tensorflow hub models are not fine-tunable; see issue.
!wget http://download.tensorflow.org/models/object_detection/tf2/20200711/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz
!tar -xf ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz
!mv ssd_resnet50_v1_fpn_640x640_coco17_tpu-8/checkpoint models/research/object_detection/test_data/
--2022-07-02 06:30:55-- http://download.tensorflow.org/models/object_detection/tf2/20200711/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz Resolving download.tensorflow.org (download.tensorflow.org)... 74.125.24.128, 2404:6800:4003:c06::80 Connecting to download.tensorflow.org (download.tensorflow.org)|74.125.24.128|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 244817203 (233M) [application/x-tar] Saving to: ‘ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz.3’ ssd_resnet50_v1_fpn 100%[===================>] 233.48M 321MB/s in 0.7s 2022-07-02 06:30:56 (321 MB/s) - ‘ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar.gz.3’ saved [244817203/244817203] mv: cannot move 'ssd_resnet50_v1_fpn_640x640_coco17_tpu-8/checkpoint' to 'models/research/object_detection/test_data/checkpoint': Directory not empty
Run the code below to load the pretrained model.
One reason it is fairly complex is that the pretrained model requires backward compatibility with TensorFlow 1.0 and because there is some added complexity for managing all the different pretrained models in this particular repository. For some documentation on the simpler and more clean semantics of saving and loading model checkpoints in TensorFlow 2.0 see this documentation
from object_detection.utils import config_util
from object_detection.builders import model_builder
import tensorflow as tf
tf.keras.backend.clear_session()
num_classes = 1
pipeline_config = 'models/research/object_detection/configs/tf2/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.config'
checkpoint_path = 'models/research/object_detection/test_data/checkpoint/ckpt-0'
configs = config_util.get_configs_from_pipeline_file(pipeline_config)
model_config = configs['model']
model_config.ssd.num_classes = num_classes
model_config.ssd.freeze_batchnorm = True
detection_model = model_builder.build(model_config=model_config, is_training=True)
fake_box_predictor = tf.compat.v2.train.Checkpoint(
_base_tower_layers_for_heads=detection_model._box_predictor._base_tower_layers_for_heads,
# _prediction_heads=detection_model._box_predictor._prediction_heads,
# (i.e., the classification head that we *will not* restore)
_box_prediction_head=detection_model._box_predictor._box_prediction_head,
)
fake_model = tf.compat.v2.train.Checkpoint(
_feature_extractor=detection_model._feature_extractor,
_box_predictor=fake_box_predictor)
ckpt = tf.compat.v2.train.Checkpoint(model=fake_model)
ckpt.restore(checkpoint_path).expect_partial()
# Run model through a dummy image so that variables are created
image, shapes = detection_model.preprocess(tf.zeros([1, 640, 640, 3]))
prediction_dict = detection_model.predict(image, shapes)
_ = detection_model.postprocess(prediction_dict, shapes)
Use the following code to make some predictions before fine-tuning. The model by default will generate 100 possible objects, each with associated scores and predicted classes.
We utilize the detect() function, which wraps the preprocessing, prediction, and postprocessing step with the tf.function dectorator so that this computation will enjoy faster performance (see this tutorial for more context).
@tf.function
def detect(input_tensor):
"""Run detection on an input image.
Args:
input_tensor: A [1, height, width, 3] Tensor of type tf.float32.
Note that height and width can be anything since the image will be
immediately resized according to the needs of the model within this
function.
Returns:
A dict containing 3 Tensors (`detection_boxes`, `detection_classes`,
and `detection_scores`).
"""
preprocessed_image, shapes = detection_model.preprocess(input_tensor)
prediction_dict = detection_model.predict(preprocessed_image, shapes)
return detection_model.postprocess(prediction_dict, shapes)
pre_ft_bb_preds = []
pre_ft_scores_preds = []
pre_ft_classes_preds = []
label_id_offset = 1
plt.figure(figsize=(20, 20))
for i in range(len(test_images_np)):
input_tensor = tf.convert_to_tensor(test_images_np[i], dtype=tf.float32)
detections = detect(input_tensor)
pre_ft_bb_preds.append(detections['detection_boxes'][0].numpy())
pre_ft_scores_preds.append(detections['detection_scores'][0].numpy())
pre_ft_classes_preds.append(detections['detection_classes'][0].numpy().astype(np.uint32) + label_id_offset)
if i < 5:
ax = plt.subplot(3, 2, i + 1)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
temp_img_copy = np.copy(test_images_np[i][0])
viz_utils.visualize_boxes_and_labels_on_image_array(
temp_img_copy,
pre_ft_bb_preds[-1],
pre_ft_classes_preds[-1],
pre_ft_scores_preds[-1],
category_index,
use_normalized_coordinates=True,
min_score_thresh=0.0
)
plt.imshow(temp_img_copy)

plt.figure(figsize=(20, 20))
for i in range(5):
ax = plt.subplot(3, 2, i + 1)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
most_confident_bb = np.argmax(pre_ft_scores_preds[i])
temp_img_copy = np.copy(test_images_np[i][0])
viz_utils.visualize_boxes_and_labels_on_image_array(
temp_img_copy,
pre_ft_bb_preds[i][most_confident_bb][None, :],
np.array([pre_ft_classes_preds[i][most_confident_bb]]),
np.array([pre_ft_scores_preds[i][most_confident_bb]]),
category_index,
use_normalized_coordinates=True,
min_score_thresh=0.0
)
plt.imshow(temp_img_copy)

The Intersection over Union is one way to measure how good a bounding box prediction is.
Complete the bounding_box_iou() function below. You will need to complete these steps in the code:
def bounding_box_iou(boxA:list, boxB:list) -> float:
"""
Computes the Intersection over Union for two bounding boxes
Args:
boxA (ymin, xmin, ymax, xmax)
boxB (ymin, xmin, ymax, xmax)
Return: intersection Over Union metric given two boxes cordinates
"""
ymin_a, xmin_a, ymax_a, xmax_a = boxA
ymin_b, xmin_b, ymax_b, xmax_b = boxB
over_x_min = max(xmin_a,xmin_b)
over_x_max = min(xmax_a,xmax_b)
over_y_min = max(ymin_a,ymin_b)
over_y_max = min(ymax_a,ymax_b)
inter = max(over_y_max-over_y_min,0)*max(over_x_max-over_x_min,0)
boxA_area = (xmax_a - xmin_a)*(ymax_a-ymin_a)
boxB_area = (xmax_b - xmin_b)*(ymax_b-ymin_b)
iou = inter/(boxA_area+boxB_area-inter)
return iou
# YOUR CODE HERE
t_gt_boxes[1][0]
array([0.27916667, 0.3140625 , 0.92916667, 0.9859375 ])
bounding_box_iou([0,0,1,1], [2,2,3,3])
0.0
assert bounding_box_iou([0,0,1,1], [0,0,1,1]) == 1
assert bounding_box_iou([0,0,1,1], [1,1,2,2]) == 0
Use the compute_best_iou_and_score() function to find the best IoU and scores of the test images.
Remember the test images are stored in t_gt_boxes, the predicted bounding boxes are stored in pre_ft_bb_preds and the prediction scores per bounding box are stored in pre_ft_scores_preds.
def compute_best_iou_and_score(gt_bounding_box, predicted_bounding_boxes, prediction_scores_per_bb):
"""
compute the best IoU and scores
"""
indv_ious = []
for bbox_idx in range(len(predicted_bounding_boxes)):
indv_ious.append(bounding_box_iou(gt_bounding_box, predicted_bounding_boxes[bbox_idx]))
if len(indv_ious) == 0:
return 0, 0
best_bounding_box = np.argmax(indv_ious)
return indv_ious[best_bounding_box], prediction_scores_per_bb[best_bounding_box]
ious = []
scores = []
# YOUR CODE HERE
for i in range(len(t_gt_boxes)):
ind_iou, pred_iou = compute_best_iou_and_score(t_gt_boxes[i][0], pre_ft_bb_preds[i], pre_ft_scores_preds[i])
ious.append(ind_iou)
scores.append(pred_iou)
print('The mean IoU on the test images is: ', np.mean(ious))
print('The associated scores are: ', np.mean(scores))
The mean IoU on the test images is: 0.7187429027710128 The associated scores are: 0.031957936
np.mean(ious)
0.7187429027710128
#assert np.isclose(np.mean(ious), .25, atol=5e-2) # Expect the mean IoU to be in the neighborhood of .25
assert np.isclose(np.mean(scores), .03, atol=1e-2)
.trainable_variables attribute of the model detection_model. How many variables are there?print(len(detection_model.trainable_variables))
269
# YOUR CODE HERE
variables_names = [v.name for v in detection_model.trainable_variables]
print(variables_names)
['WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalBoxHead/BoxPredictor/kernel:0', 'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalBoxHead/BoxPredictor/bias:0', 'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalClassHead/ClassPredictor/kernel:0', 'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalClassHead/ClassPredictor/bias:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/kernel:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/kernel:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/kernel:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/kernel:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_0/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_1/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_2/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/BoxPredictionTower/conv2d_3/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/kernel:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/kernel:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/kernel:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/kernel:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_0/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_0/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_1/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_1/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_2/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_2/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_3/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_3/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_0/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_1/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_2/BatchNorm/feature_4/beta:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_4/gamma:0', 'WeightSharedConvolutionalBoxPredictor/ClassPredictionTower/conv2d_3/BatchNorm/feature_4/beta:0', 'ResNet50V1_FPN/bottom_up_block5_conv/kernel:0', 'ResNet50V1_FPN/bottom_up_block5_batchnorm/gamma:0', 'ResNet50V1_FPN/bottom_up_block5_batchnorm/beta:0', 'ResNet50V1_FPN/bottom_up_block6_conv/kernel:0', 'ResNet50V1_FPN/bottom_up_block6_batchnorm/gamma:0', 'ResNet50V1_FPN/bottom_up_block6_batchnorm/beta:0', 'conv1_conv/kernel:0', 'conv1_bn/gamma:0', 'conv1_bn/beta:0', 'conv2_block1_1_conv/kernel:0', 'conv2_block1_1_bn/gamma:0', 'conv2_block1_1_bn/beta:0', 'conv2_block1_2_conv/kernel:0', 'conv2_block1_2_bn/gamma:0', 'conv2_block1_2_bn/beta:0', 'conv2_block1_0_conv/kernel:0', 'conv2_block1_3_conv/kernel:0', 'conv2_block1_0_bn/gamma:0', 'conv2_block1_0_bn/beta:0', 'conv2_block1_3_bn/gamma:0', 'conv2_block1_3_bn/beta:0', 'conv2_block2_1_conv/kernel:0', 'conv2_block2_1_bn/gamma:0', 'conv2_block2_1_bn/beta:0', 'conv2_block2_2_conv/kernel:0', 'conv2_block2_2_bn/gamma:0', 'conv2_block2_2_bn/beta:0', 'conv2_block2_3_conv/kernel:0', 'conv2_block2_3_bn/gamma:0', 'conv2_block2_3_bn/beta:0', 'conv2_block3_1_conv/kernel:0', 'conv2_block3_1_bn/gamma:0', 'conv2_block3_1_bn/beta:0', 'conv2_block3_2_conv/kernel:0', 'conv2_block3_2_bn/gamma:0', 'conv2_block3_2_bn/beta:0', 'conv2_block3_3_conv/kernel:0', 'conv2_block3_3_bn/gamma:0', 'conv2_block3_3_bn/beta:0', 'conv3_block1_1_conv/kernel:0', 'conv3_block1_1_bn/gamma:0', 'conv3_block1_1_bn/beta:0', 'conv3_block1_2_conv/kernel:0', 'conv3_block1_2_bn/gamma:0', 'conv3_block1_2_bn/beta:0', 'conv3_block1_0_conv/kernel:0', 'conv3_block1_3_conv/kernel:0', 'conv3_block1_0_bn/gamma:0', 'conv3_block1_0_bn/beta:0', 'conv3_block1_3_bn/gamma:0', 'conv3_block1_3_bn/beta:0', 'conv3_block2_1_conv/kernel:0', 'conv3_block2_1_bn/gamma:0', 'conv3_block2_1_bn/beta:0', 'conv3_block2_2_conv/kernel:0', 'conv3_block2_2_bn/gamma:0', 'conv3_block2_2_bn/beta:0', 'conv3_block2_3_conv/kernel:0', 'conv3_block2_3_bn/gamma:0', 'conv3_block2_3_bn/beta:0', 'conv3_block3_1_conv/kernel:0', 'conv3_block3_1_bn/gamma:0', 'conv3_block3_1_bn/beta:0', 'conv3_block3_2_conv/kernel:0', 'conv3_block3_2_bn/gamma:0', 'conv3_block3_2_bn/beta:0', 'conv3_block3_3_conv/kernel:0', 'conv3_block3_3_bn/gamma:0', 'conv3_block3_3_bn/beta:0', 'conv3_block4_1_conv/kernel:0', 'conv3_block4_1_bn/gamma:0', 'conv3_block4_1_bn/beta:0', 'conv3_block4_2_conv/kernel:0', 'conv3_block4_2_bn/gamma:0', 'conv3_block4_2_bn/beta:0', 'conv3_block4_3_conv/kernel:0', 'conv3_block4_3_bn/gamma:0', 'conv3_block4_3_bn/beta:0', 'conv4_block1_1_conv/kernel:0', 'conv4_block1_1_bn/gamma:0', 'conv4_block1_1_bn/beta:0', 'conv4_block1_2_conv/kernel:0', 'conv4_block1_2_bn/gamma:0', 'conv4_block1_2_bn/beta:0', 'conv4_block1_0_conv/kernel:0', 'conv4_block1_3_conv/kernel:0', 'conv4_block1_0_bn/gamma:0', 'conv4_block1_0_bn/beta:0', 'conv4_block1_3_bn/gamma:0', 'conv4_block1_3_bn/beta:0', 'conv4_block2_1_conv/kernel:0', 'conv4_block2_1_bn/gamma:0', 'conv4_block2_1_bn/beta:0', 'conv4_block2_2_conv/kernel:0', 'conv4_block2_2_bn/gamma:0', 'conv4_block2_2_bn/beta:0', 'conv4_block2_3_conv/kernel:0', 'conv4_block2_3_bn/gamma:0', 'conv4_block2_3_bn/beta:0', 'conv4_block3_1_conv/kernel:0', 'conv4_block3_1_bn/gamma:0', 'conv4_block3_1_bn/beta:0', 'conv4_block3_2_conv/kernel:0', 'conv4_block3_2_bn/gamma:0', 'conv4_block3_2_bn/beta:0', 'conv4_block3_3_conv/kernel:0', 'conv4_block3_3_bn/gamma:0', 'conv4_block3_3_bn/beta:0', 'conv4_block4_1_conv/kernel:0', 'conv4_block4_1_bn/gamma:0', 'conv4_block4_1_bn/beta:0', 'conv4_block4_2_conv/kernel:0', 'conv4_block4_2_bn/gamma:0', 'conv4_block4_2_bn/beta:0', 'conv4_block4_3_conv/kernel:0', 'conv4_block4_3_bn/gamma:0', 'conv4_block4_3_bn/beta:0', 'conv4_block5_1_conv/kernel:0', 'conv4_block5_1_bn/gamma:0', 'conv4_block5_1_bn/beta:0', 'conv4_block5_2_conv/kernel:0', 'conv4_block5_2_bn/gamma:0', 'conv4_block5_2_bn/beta:0', 'conv4_block5_3_conv/kernel:0', 'conv4_block5_3_bn/gamma:0', 'conv4_block5_3_bn/beta:0', 'conv4_block6_1_conv/kernel:0', 'conv4_block6_1_bn/gamma:0', 'conv4_block6_1_bn/beta:0', 'conv4_block6_2_conv/kernel:0', 'conv4_block6_2_bn/gamma:0', 'conv4_block6_2_bn/beta:0', 'conv4_block6_3_conv/kernel:0', 'conv4_block6_3_bn/gamma:0', 'conv4_block6_3_bn/beta:0', 'conv5_block1_1_conv/kernel:0', 'conv5_block1_1_bn/gamma:0', 'conv5_block1_1_bn/beta:0', 'conv5_block1_2_conv/kernel:0', 'conv5_block1_2_bn/gamma:0', 'conv5_block1_2_bn/beta:0', 'conv5_block1_0_conv/kernel:0', 'conv5_block1_3_conv/kernel:0', 'conv5_block1_0_bn/gamma:0', 'conv5_block1_0_bn/beta:0', 'conv5_block1_3_bn/gamma:0', 'conv5_block1_3_bn/beta:0', 'conv5_block2_1_conv/kernel:0', 'conv5_block2_1_bn/gamma:0', 'conv5_block2_1_bn/beta:0', 'conv5_block2_2_conv/kernel:0', 'conv5_block2_2_bn/gamma:0', 'conv5_block2_2_bn/beta:0', 'conv5_block2_3_conv/kernel:0', 'conv5_block2_3_bn/gamma:0', 'conv5_block2_3_bn/beta:0', 'conv5_block3_1_conv/kernel:0', 'conv5_block3_1_bn/gamma:0', 'conv5_block3_1_bn/beta:0', 'conv5_block3_2_conv/kernel:0', 'conv5_block3_2_bn/gamma:0', 'conv5_block3_2_bn/beta:0', 'conv5_block3_3_conv/kernel:0', 'conv5_block3_3_bn/gamma:0', 'conv5_block3_3_bn/beta:0', 'ResNet50V1_FPN/FeatureMaps/top_down/projection_3/kernel:0', 'ResNet50V1_FPN/FeatureMaps/top_down/projection_3/bias:0', 'ResNet50V1_FPN/FeatureMaps/top_down/projection_2/kernel:0', 'ResNet50V1_FPN/FeatureMaps/top_down/projection_2/bias:0', 'ResNet50V1_FPN/FeatureMaps/top_down/projection_1/kernel:0', 'ResNet50V1_FPN/FeatureMaps/top_down/projection_1/bias:0', 'ResNet50V1_FPN/FeatureMaps/top_down/smoothing_2_conv/kernel:0', 'ResNet50V1_FPN/FeatureMaps/top_down/smoothing_2_batchnorm/gamma:0', 'ResNet50V1_FPN/FeatureMaps/top_down/smoothing_2_batchnorm/beta:0', 'ResNet50V1_FPN/FeatureMaps/top_down/smoothing_1_conv/kernel:0', 'ResNet50V1_FPN/FeatureMaps/top_down/smoothing_1_batchnorm/gamma:0', 'ResNet50V1_FPN/FeatureMaps/top_down/smoothing_1_batchnorm/beta:0']
We're going to fine tune the WeightSharedConvolutionalBoxPredictor layer only. Don't worry about why specifically this layer for the purposes of this tutorial. When you fine tune your own models, picking which parts of it to fine tune are a combination of the inductive bias you impose, and the result of hyperparameter optimization.
Complete the get_model_train_step_function() function.
.predict() method to generate predictions and save as prediction_dict..loss() method and save as losses_dict.total_loss equal to the sum of localization_loss and classification_loss from the losses dictionary.def get_model_train_step_function(model, optimizer, vars_to_fine_tune):
"""Get a tf.function for training step."""
# Use tf.function for a bit of speed.
# Comment out the tf.function decorator if you want the inside of the
# function to run eagerly.
@tf.function
def train_step_fn(image_tensors, groundtruth_boxes_list, groundtruth_classes_list):
"""A single training iteration.
Args:
image_tensors: A list of [1, height, width, 3] Tensor of type tf.float32.
Note that the height and width can vary across images, as they are
reshaped within this function to be 640x640.
groundtruth_boxes_list: A list of Tensors of shape [N_i, 4] with type
tf.float32 representing groundtruth boxes for each image in the batch.
groundtruth_classes_list: A list of Tensors of shape [N_i, num_classes]
with type tf.float32 representing groundtruth classes for each image in
the batch.
Returns:
A scalar tensor representing the total loss for the input batch.
"""
shapes = tf.constant(batch_size * [[640, 640, 3]], dtype=tf.int32)
model.provide_groundtruth(
groundtruth_boxes_list=groundtruth_boxes_list,
groundtruth_classes_list=groundtruth_classes_list)
with tf.GradientTape() as tape:
preprocessed_images = tf.concat(
[model.preprocess(image_tensor)[0] #[detection_model.preprocess(image_tensor)[0]
for image_tensor in image_tensors], axis=0)
prediction_dict = model.predict(preprocessed_images,shapes)# YOUR CODE HERE
losses_dict = model.loss(prediction_dict,shapes)# YOUR CODE HERE
total_loss = sum(losses_dict.values())# YOUR CODE HERE
gradients = tape.gradient(total_loss, vars_to_fine_tune)
optimizer.apply_gradients(zip(gradients, vars_to_fine_tune))
return total_loss
return train_step_fn
batch_size = 10
learning_rate = 0.001
num_batches = 100
Complete the following code by completing the optimizer and train_step_fn.
optimizer.get_model_train_step_function() function to create train_step_fn.trainable_variables = detection_model.trainable_variables
to_fine_tune = []
prefixes_to_train = [
'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalBoxHead',
'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalClassHead']
for var in trainable_variables:
if any([var.name.startswith(prefix) for prefix in prefixes_to_train]):
to_fine_tune.append(var)
optimizer = tf.keras.optimizers.SGD(
learning_rate=0.001,
momentum=0.0,
nesterov=False,
name='SGD')# YOUR CODE HERE
train_step_fn=get_model_train_step_function(detection_model, optimizer, trainable_variables) # YOUR CODE HERE
import random
for idx in range(num_batches):
all_keys = list(range(len(train_images_np)))
random.shuffle(all_keys)
example_keys = all_keys[:batch_size]
gt_boxes_list = [gt_box_tensors[key] for key in example_keys]
gt_classes_list = [gt_classes_one_hot_tensors[key] for key in example_keys]
image_tensors = [train_image_tensors[key] for key in example_keys]
total_loss = train_step_fn(image_tensors, gt_boxes_list, gt_classes_list)
if idx % 10 == 0:
print('batch ' + str(idx) + ' of ' + str(num_batches) + ', loss=' + str(total_loss.numpy()), flush=True)
batch 0 of 100, loss=1.1432129 batch 10 of 100, loss=0.40608844 batch 20 of 100, loss=0.15999468 batch 30 of 100, loss=0.11909683 batch 40 of 100, loss=0.09815807 batch 50 of 100, loss=0.084696345 batch 60 of 100, loss=0.07487132 batch 70 of 100, loss=0.067269884 batch 80 of 100, loss=0.06121165 batch 90 of 100, loss=0.056245066
post_ft_bb_preds = []
post_ft_scores_preds = []
post_ft_classes_preds = []
plt.figure(figsize=(20, 20))
for i in range(len(test_images_np)):
input_tensor = tf.convert_to_tensor(test_images_np[i], dtype=tf.float32)
detections = detect(input_tensor)
post_ft_bb_preds.append(detections['detection_boxes'][0].numpy())
post_ft_scores_preds.append(detections['detection_scores'][0].numpy())
post_ft_classes_preds.append(detections['detection_classes'][0].numpy().astype(np.uint32) + label_id_offset)
if i < 5:
ax = plt.subplot(3, 2, i + 1)
ax.axes.xaxis.set_visible(False)
ax.axes.yaxis.set_visible(False)
temp_img_copy = np.copy(test_images_np[i][0])
most_confident_bb = np.argmax(post_ft_scores_preds[i])
viz_utils.visualize_boxes_and_labels_on_image_array(
temp_img_copy,
post_ft_bb_preds[i][most_confident_bb][None, :],
np.array([post_ft_classes_preds[i][most_confident_bb]]),
np.array([post_ft_scores_preds[i][most_confident_bb]]),
category_index,
use_normalized_coordinates=True,
min_score_thresh=0.0
)
plt.imshow(temp_img_copy)

ious = []
scores = []
# YOUR CODE HERE
for i in range(len(gt_boxes_list)):
ind_iou, pred_iou = compute_best_iou_and_score(gt_boxes_list[i][0], post_ft_bb_preds[i], post_ft_scores_preds[i])
ious.append(ind_iou)
scores.append(pred_iou)
print('The mean IoU on the test images is: ', np.mean(ious))
print('The associated scores are: ', np.mean(scores))
The mean IoU on the test images is: 0.6751941 The associated scores are: 0.058383685
assert np.isclose(np.mean(ious), .48, atol=1e-1)
assert np.isclose(np.mean(scores), .03, atol=1e-2)
--------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-192-985d76c79ce4> in <module>() 1 #assert np.isclose(np.mean(ious), .48, atol=1e-1) ----> 2 assert np.isclose(np.mean(scores), .03, atol=1e-2) AssertionError:
The notebook is adapted from Tensorflow models (the demo).
SSD (original paper: single shot multibox detector)
How to Train Your Own Object Detector Using TensorFlow Object Detection API
The assignment does not focus on image classification, the following three links are useful if you would like to quickly go over the fundamentals on the subject.